3.2 Data submission

Data archives can offer different ways of submitting data for review and appraisal. In each case
- researchers should be informed and instructed on what to do,
- data transfer should be done in a secure way,
- and all incoming material should be administered and stored appropriately.
What solution a data archive chooses to meet these requirements, might depend on, for example, the number of incoming datasets, and the number of staff, available IT resources and support and, to some extent, legacy and tradition.
The large size of an average dataset or the possibility that data might be sensitive can complicate data submission and might imply a need for customised solutions for data with these characteristics.
There are certainly advantages of using formalised and technically advanced solutions like webforms, compared to researchers sending data sets and documentation by e-mail. There are disadvantages as well.
| Advantages | Disadvantages |
|
+ Metadata can be entered in a web form in accordance with the metadata profile(s) that the data archive supports, and automatically validated in the process of entry (or later after transfer to metadata database); + Data can be directly sent to a quarantine area to be checked for viruses in a secure environment, before being saved to another working area; + Checking the identity of depositors through federated identification can be done automatically; + Automatic notification on an incoming submission to a certain number of e-mail addresses is possible; that might be good in a decentralised data archive or when the Pre-ingest activities are shared between several institutions, like central data archive and university RDM support. This allows for quick coordination and gives an opportunity to give first feedback quickly; + Possible to add workflow management in such a system (like, send follow-up questions to data producers, have check-lists for data & metadata checks). |
− Complicated and not straightforward interface for data depositors (compared to e-mail, for example); − The standard solution usually is not applicable for all data (e.g., large data, sensitive data) and alternative solutions are necessarily complicating the process; − Process can easily loose transparency and get too complicated, if too many roles are involved (like data producer, data manager, (meta)data reviewer 1, (meta)data reviewer 2 etc.) Overview of workflow on personal ‘dashboard’ can get difficult to manage. − Submitted “test” versions of data descriptions and datasets that never get completed and submitted, and therefore need eventually to be deleted, take time and effort to identify and sort out. |
3.2.1 Informing depositors
Researchers should have easy access to information on the data archive website on
- submission requirements, such as what data are accepted according to the Acquisition requirements; what file formats for data are accepted in the archive, what documentation should be included, what legal and ethical requirements should be followed;
- description of the main steps in the deposit process and what is expected from them, and what will happen with their data;
- instructions how to proceed;
- information on how data will be processed by the archive; timeline of when they would be published.
Detailed instructions, along with access to data description and data and documentation upload may be available openly or after registration and identification.
Researchers interested in data deposit may be instructed to leave their contact information or contact the archive for further information. This approach might be useful if you expect that the archive’s potential depositors might benefit from discussing the data curation profile beforehand. It might be time consuming but would help to clarify any issues and misunderstandings before the data are transferred.
3.2.2 Data transfer
The result of this step should be the secure and trusted arrival of well-described data and documentation in the data archive.
Digital content should be submitted to archive digitally (for example, via cloud, ftp or similar), except when it is not possible because of the size or sensitive character of data. Transfer of data, documentation and description of data should be possible to do securely and minimizing data corruption risks.
Access to the data archive’s deposit system can be restricted, for example, protected by a password, or open for anyone. The use of identity federation (researcher could identify in a data archive with password from university or research institute) would mean that the depositors' identity and institutional affiliation is controlled automatically.
Data description, data sets and documentation can be transferred to the data archive with little involvement from data archive staff, e.g., using well annotated and instructive web-forms for data description and file upload. It can also be done in more informal ways, like electronically via e-mail or mail, as external hard drives, and metadata can be delivered in paper. The advantage of the latter is flexibility and personal approach, but some transparency is lost. Disadvantages to this kind of data transfer are related to manual work by archive staff needed to transfer metadata into the databases the archive uses, and upload data.
In addition to discipline-specific metadata, the description might include administrative information important for reviewing and appraising data submission, for example,
- if the depositor's institution has an agreement with your data archive,
- if data are linked to data already published through the data archive,
- if data includes personal direct identifiers.
How we do it: Data submission in DORIS web interface in SND
After confirming their identity with university or research institute ID, researchers can create data description, and upload or link documentation and data in web interface of DORIS, SND’s Data Organisation and Information System. SND’s Data submission form for social sciences data includes metadata fields that are part of SNDs metadata profile based on DDI3, CESSDA Metadata Model (CMM, Akdeniz, Esra et al. 2021) as well as questions, where
- data includes personal data,
- Ethical Board has reviewed the project,
- there is related data already described in SND’s data Catalogue.
Special cases: sensitive data, large data
Some data may need special solutions for data transfer. Such are, for example, large data files or sensitive data.
Therefore, it would be good to have a possibility for data producers to indicate during the data transfer process in, for example, a data description form, and researchers should be given additional instructions on the data upload interface.
This information can be collected also, for example, in data curation interviews, conducted by some data archives with potential data depositors before the data submission process is initiated.
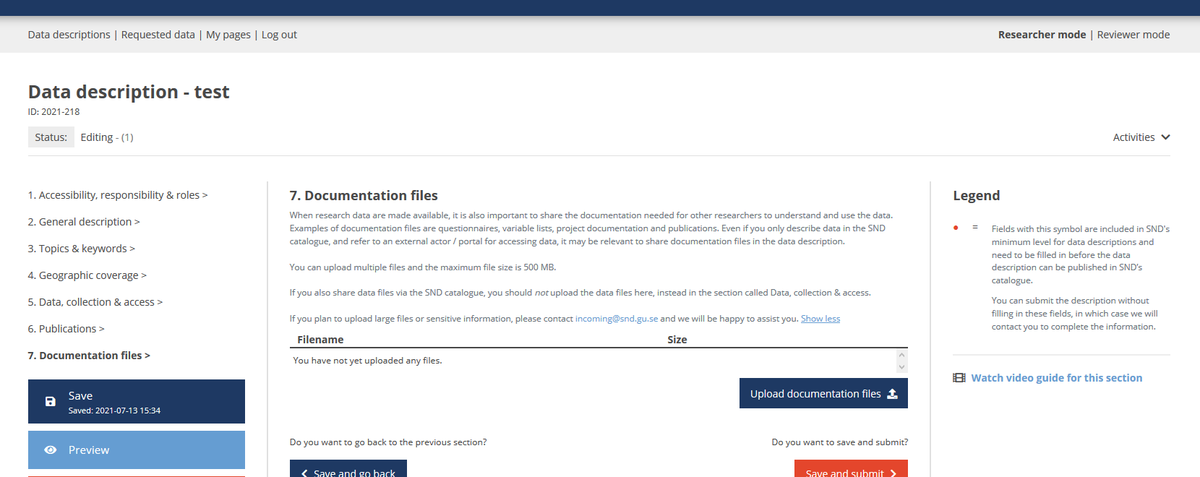
How do we do it: Example SND, screenshot from web form instructions on submitting sensitive information
In case of data deposit involves protected or sensitive information or large data files, depositors are instructed to contact SND staff for a customized solution (for large data sets above 500MB, it can be an ftp server).
3.2.3 Administering incoming data
All incoming material in the data archive should be treated in a transparent and accountable way.
Alert
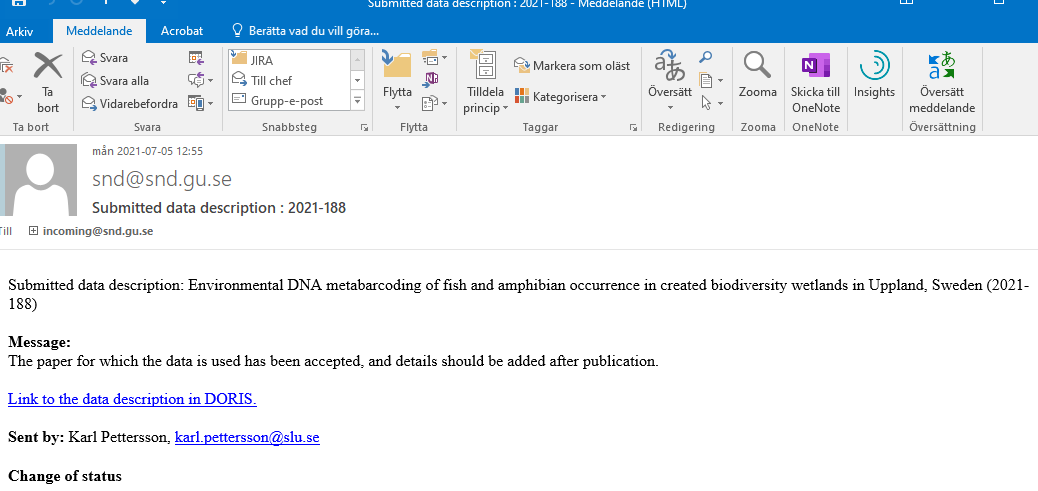
The data archive should be alerted about incoming data. Technically it can be done in different ways, but the most important is that the Pre-ingest/Acquisition staff gets the information on incoming data submission. It could be, for example, an e-mail communication going directly to the Pre-Ingest group or a smaller subgroup of staff.
How we do it: Example of incoming data alert e-mail going to Research Data Advisory group, SND
Assign preliminary ID- number
Incoming data material should get a preliminary unique number assigned for administration during the Pre-ingest/Acquisition phase. The previous example from SND shows an automatically assigned preliminary number, but in other data archives it might be done manually as well.
Response / receipt to the depositor
To ensure good and trusted service, data depositors should get a timely response or a receipt, confirming the successful transfer of data and other material. It may include a ‘Thank you’ and an approximate period when the message of acceptance or rejection from the data archive can be expected.
The letter may include a short description of the next steps of Pre-ingest that may require the depositor’s involvement. It does not have to be a long and personalised message at this stage, it depends on the praxis and etiquette expected and legal requirements.
Assigning responsible staff
Staff responsible for data appraisal, review and quality checks should be assigned. The process may be more or less formal or technically more or less advanced. The responsible staff should be recorded in the database or app used in administering workflow in Pre-ingest. It can be, for example, an Excel file, a web-interface, or a physical board with post-its listing submissions, responsible staff on review timeline. The aim of this is to ensure accountability of the revision process, and continuity in case of changes of staff.
Transfer of data to temporary storage solution
Before the revision, data and documentation should be moved to a temporary storage solution, preferably, ensuring that the files have not been transformed during this process (for example, by using check-sum - UK Data Archive 2013).
Transfer can be done automatically or manually. This temporary storage area could be considered ‘quarantine’ before the virus checks. If virus checks are done automatically upon receipt, data can be downloaded manually, directly to the temporary storage area for Pre-ingest. Data and documentation can stay in this storage during the review and appraisal process.