1.8 What is the process of archiving from beginning to end?
The Open Archival Information System (OAIS) can help archives define their working process
The Reference Model for an Open Archival Information System (OAIS) is a standard in digital preservation, and it is also known as ISO 14721:2025. The intention behind OAIS is to determine the requirements for an archive or repository to provide long-term preservation of digital information and to support the development of additional digital preservation standards.
OAIS defines an archive as consisting of an organization of people and systems. The standard defines a set of responsibilities that an OAIS archive must fulfil to preserve information.
The CESSDA archives are different in size and capacity but they have a common goal of making research data more accessible and findable in the short run as well as in the long run, and OAIS serves as a guidance to this end.
Open Archival Information System - OAIS
The OAIS model distinguishes three complex information objects:
-
Submission Information Package (SIP)
The Submission Information Package (SIP) is the package that a data producer, such as a researcher or data steward sends to an archive. Usually the archive has set some requirements that the producer has to follow about the form, the submission tool and the content of the data and its documentation. You can read more about this in Chapter 4 for more information on the ingest phase.
-
Archival Information Package (AIP)
After submission, the package is transformed within the archive into one or more Archival Information Packages (AIPs) for preservation. In this phase the data and documentation are transformed into archival, long-term preservation formats and archival storage. This involves, for example, changing formats into new, long-term preservation formats, making various versions of documents, and anonymisation.
-
Dissemination Information Package (DIP)
The Dissemination Information Package (DIP) is the part of the AIP that the archive provides to its consumers, by preparing the data and documentation for dissemination and making it available to users or visitors.
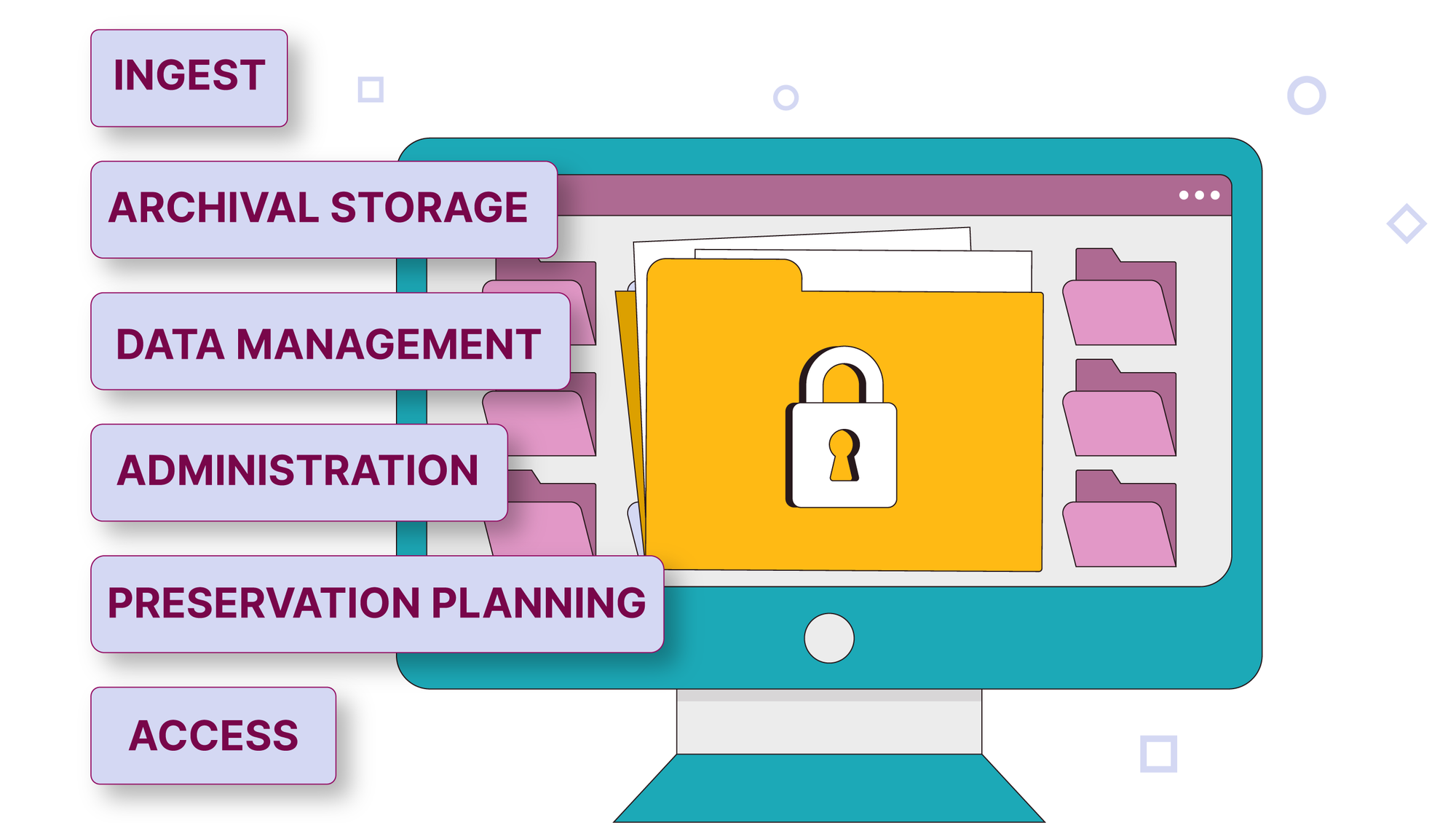
Archival functions
The OAIS Reference model has six main functions: Ingest (accepting data), Archival Storage (long-term storage and maintenance), Data Management (managing metadata), Administration (day-to-day management), Preservation Planning (ensuring long-term viability), and Access (providing user access) .
These functions give us a better insight into how the work in OAIS compliant data archives proceeds:
- Ingest:
the archive receives data and metadata from a producer and packages it for storage. A data archivist checks the data, its format, documentation, metadata and its licence and creates the additional documentation needed for the archiving purposes.
- Archival storage:
the archive stores, maintains and retrieves data documentation and the data, assigns them to long-term storage.
- Data management:
the archive maintains and updates the database.
- Administration:
these are the daily operations of the archive. It processes submissions and agreements with data producers, manages the software systems, develops policies and standards or compliance to such, and handles customer service.
- Preservation planning:
the archive keeps the archived data accessible and understandable in the long term, even if the original computing system becomes obsolete. To this end, it develops detailed preservation/migration plans, and recommendations on updates and migration.
- Access:
the archive allows users to find data and data documentation and to retrieve these from the archive.
Find out more about your archive
Here are some questions you can ask yourself to learn more about your archive:
- Does your archive implement the OAIS model fully?
- Which OAIS function does your archive find the most challenging and why?
- How are different functions implemented in your archive?
- Which PID(s) does your archive use?
Expert tips
Watch this video 'What Are Persistent Identifiers and Why to Use Them?' by FAIRsFAIR EU (2022).